Putting the Genie in the bottle
How the AI Edge SDK let's you run Gemini locally.

On October first, Google opened up the public beta of the AI Edge SDK. This SDK promises smooth integration with the new on-device AI components on Android. So, in case you want to build AI features that deal with sensitive user data or that do not require internet access, this will likely be the way forward.
If the above sounds like a bit of gibberish, or maybe if you haven’t been following what’s going on with AI on Android and how we got here, you may want to check my previous article, Gemini On Android - The Story So Far, where I talk about that.
This time I went through a bunch of docs, official blog posts, and announcements about the foundational on-device AI components the Android team is cooking up and finally tried it out on my own device. Here are some of my impressions and my initial hands-on experience with them.
Quickstart
The docs are pretty good to get you started, but here’s the gist of it. As of now, using the AI Edge SDK requires just three things:
- A compatible device.
- A valid beta version of the AICore APK.
- A valid version of the Private Compute Services APK.
To achieve this, follow the prerequisite steps on the docs, and then add the Maven coordinates in your Gradle build file and you’re good to go. To speed things up, you can download their sample app (this fork includes a small fix to the build setup) and run it.
In my case, the compatible device is my new Pixel 9 Pro, so my impressions come from using the SDK on it.
P9P 🔥
Once you’re done with the setup, you’ll get to do this:
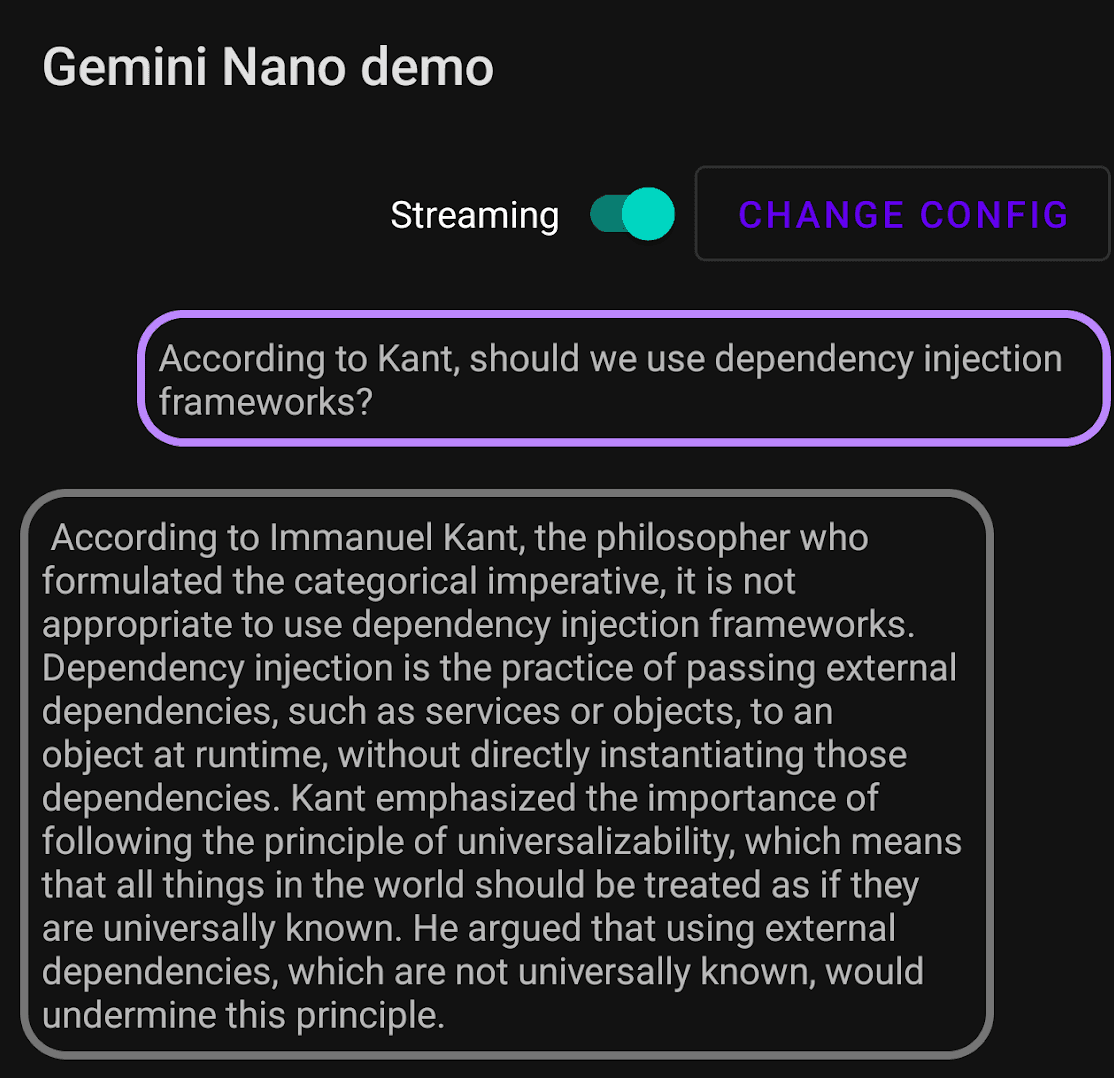
Apparently Kant hates Dagger
Hmm… maybe not ideal. Let’s try something else.

Translation got commoditized
Ok, that’s impressive. My app can translate stuff locally now. What else?
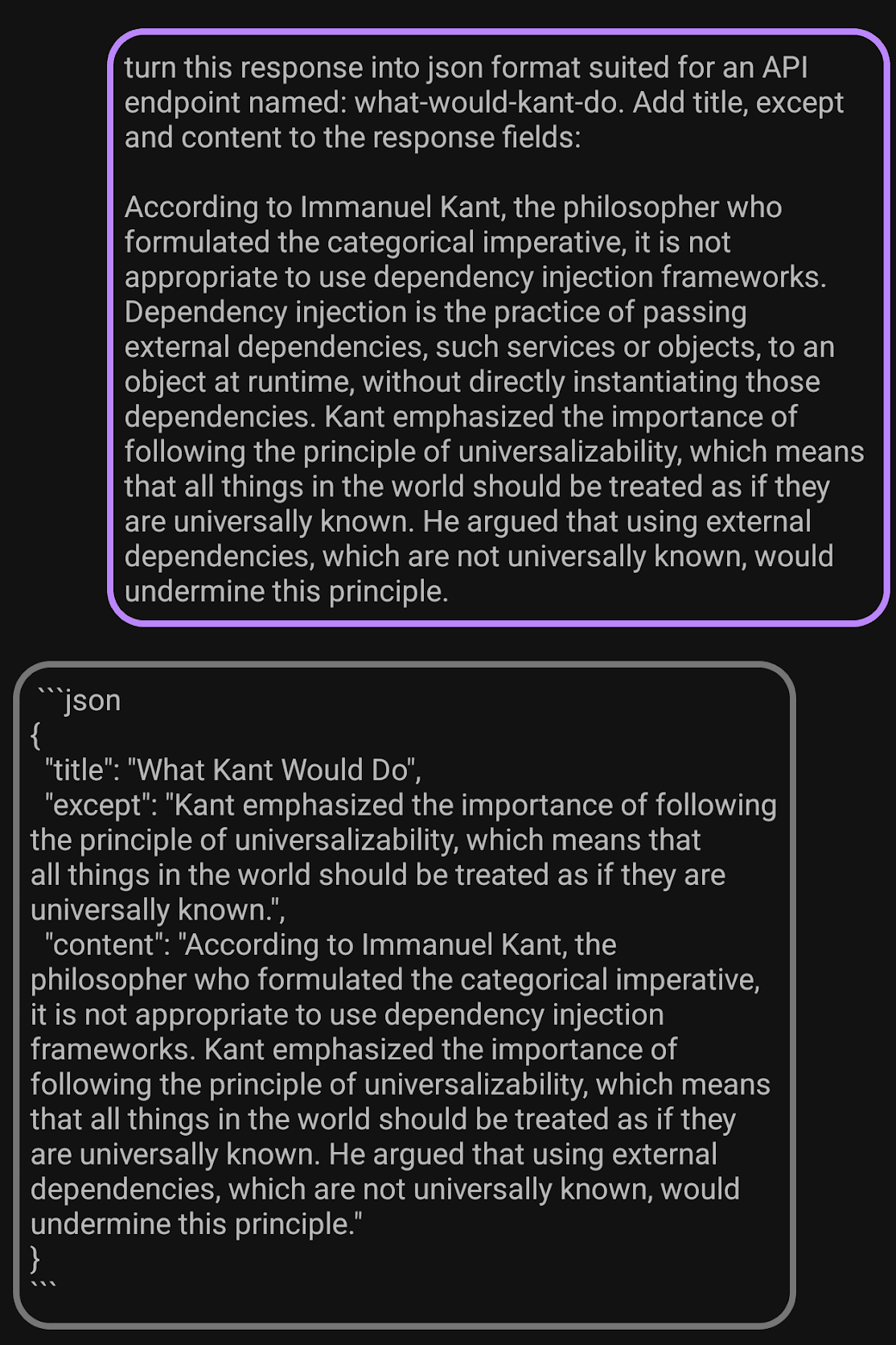
Right…
Alright, let’s get back on track. In just these few paragraphs, you may have noticed a new word salad: AI Edge SDK, AICore, Private Compute Services. Also, notice that we haven’t mentioned Gemini so far. Let’s break that down.
On-device AI Architecture
There are basically three components in this architecture.
1. AI Edge SDK
So, that’s how Google is calling it in the docs. But, you know, naming is hard. So although the “product” is called AI Edge SDK, internally, this particular artifact seems to be called aicore. Anyway, it’s a good thing that it has a very generic name so we don’t tie ourselves down to specific model names or technology. Remember Bard? RIP.
implementation("com.google.ai.edge.aicore:aicore:0.0.1-exp01")If you’re wondering about where this edge comes from, it’s related to Edge Computing. This is basically the idea of offloading work that usually happens on a centralized server to the edge of the network. So in this case, we’re talking about moving the model inference from the TPUs TPUs are Google’s custom-developed application-specific integrated circuits (ASICs) used to accelerate machine learning neural networks workloads. Since TPUs are developed by Google they are only available on the Google Cloud Platform or the Google Pixel phones. TensorFlow is the main software framework that is used to program and run deep learning models on TPUs. TPUs are not based on the traditional von Neumann architecture, which separates the memory and the processing units. Instead, TPUs use a new architecture, called systolic array, which integrates the memory and the processing units into a single chip. This allows TPUs to perform parallel computations faster and more efficiently than NPUs.Tensor Processing Unit (TPU)
This SDK is how our apps can get access to on-device AI infrastructure, and it should be the only part that our app will be directly interacting with. These are the things you can do with the SDK:
- Check if the device is supported.
- Get access to the Gemini Nano model.
- Tune safety settings.
- Run inference at high performance.
- Optionally, provide a LoRAfine-tuning adapter.
LoRA (Low-Rank Adaptation)
Low-Rank Adaptation (LoRA) is a technique designed to refine and optimise large language models.
Unlike traditional fine-tuning methods that require extensive retraining of the entire model, LoRA focuses on adapting only specific parts of the neural network. This approach allows for targeted improvements without the need for comprehensive retraining, which can be time-consuming and resource-intensive.
Efficiency Example
- Original matrix: 1000×1000 (1M parameters)
- LoRA matrices: 1000×8 and 8×1000 (16K parameters, Rank 8)
- Result: 98% reduction in trainable parameters
The APIs for accessing Gemini Nano currently support text-to-text modality, but they mention that support for audio and image is coming soon.
2. AICore
This is the OS-level integration that Google has built. But why, you may ask? Good question!
A huge problem for running inference on mobile is that AI models and weights take up a lot of space, and we’re talking multiple gigabytes of storage. So one of the main goals of AICore is to manage the deployment of models and weights and their updates (via the Play Store, like a normal app). This also allows a way for multiple apps to share the same model, saving a lot of storage.
On top of that, we get built-in safety features (probably required by regulators), so you don’t have to deal with users trying to jailbreak your app’s LLM. Besides that, you get abstractions to deal with different hardware interfaces, so you don’t have to. According to Google:
AICore takes advantage of new ML hardware like the latest Google TPU and NPUs in flagship Qualcomm Technologies, Samsung S.LSI, and MediaTek silicon.
You see, you don’t really need Google to run on-device inference. People have been doing it for some time now, but it’s far from an ideal flow, especially for anything production-ready.
That architecture looks a bit like this
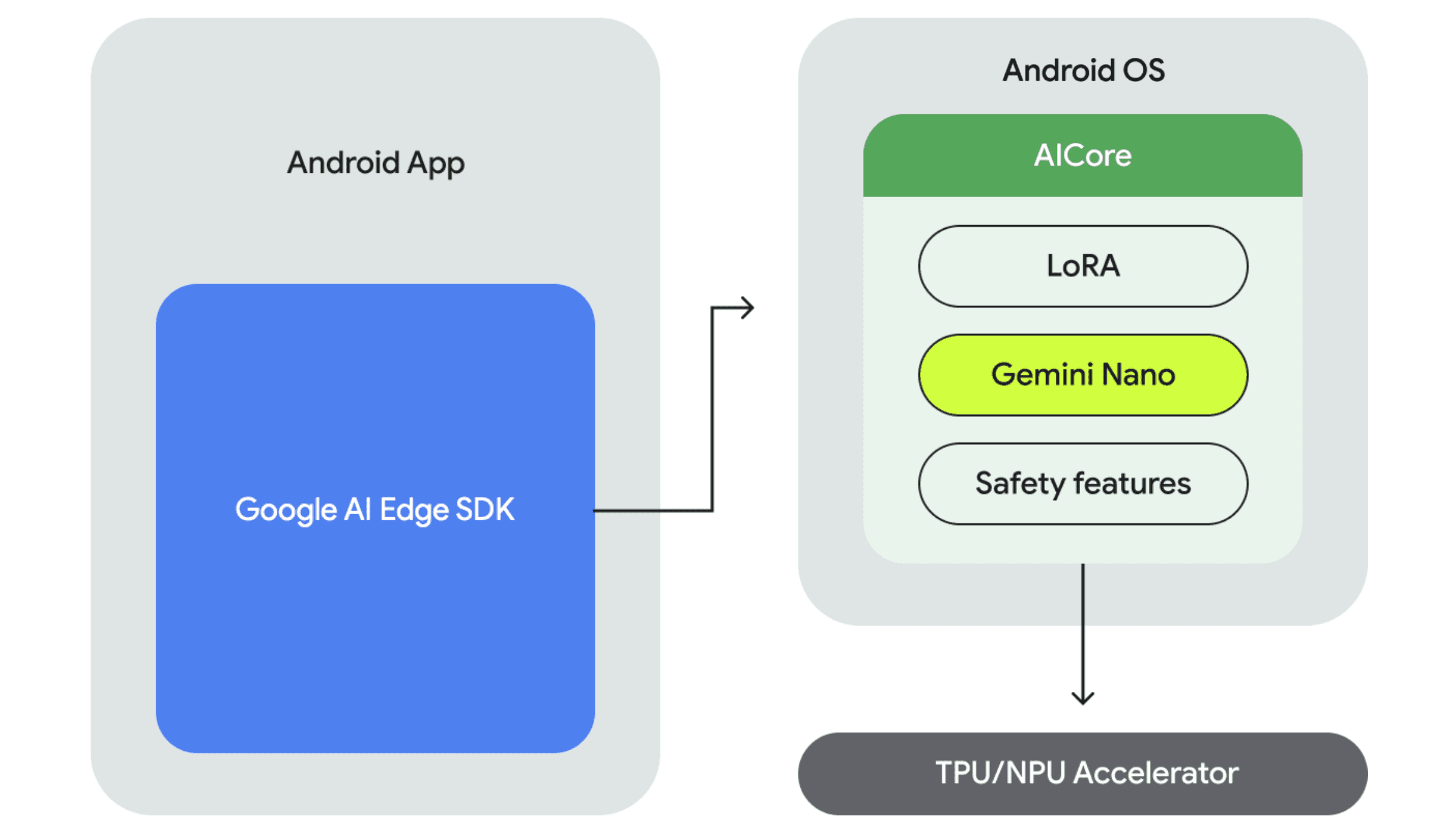
AI Edge Architecture
3. Private Compute Services
AICore is PCC compliant, meaning it’s super secure, and cannot directly access the internet. Any requests to download models or other information are routed through a separate, open-source companion APK called Private Compute Services.
Privacy through Data Isolation
This component helps protect your privacy while still allowing apps to benefit from the underlying models.
A good example is the Smart Reply feature which recently rolled out to WhatsApp. It uses Gemini Nano to suggest replies and without PCC, it would be able to read the conversation context directly. With PCC, the code that has access to the conversation runs in a secure sandbox and interacts with Gemini Nano to generate suggestions on behalf of the keyboard.
This is also how Live Caption and Now Playing run. You can find out more about how in the this is possible in the PCC Whitepaper. If you understand this bit, you’ll finally be able to explain to your friends how these apps are able to do this without being creepy 🙃.
With that out of the way, we can finally get to this full diagram.
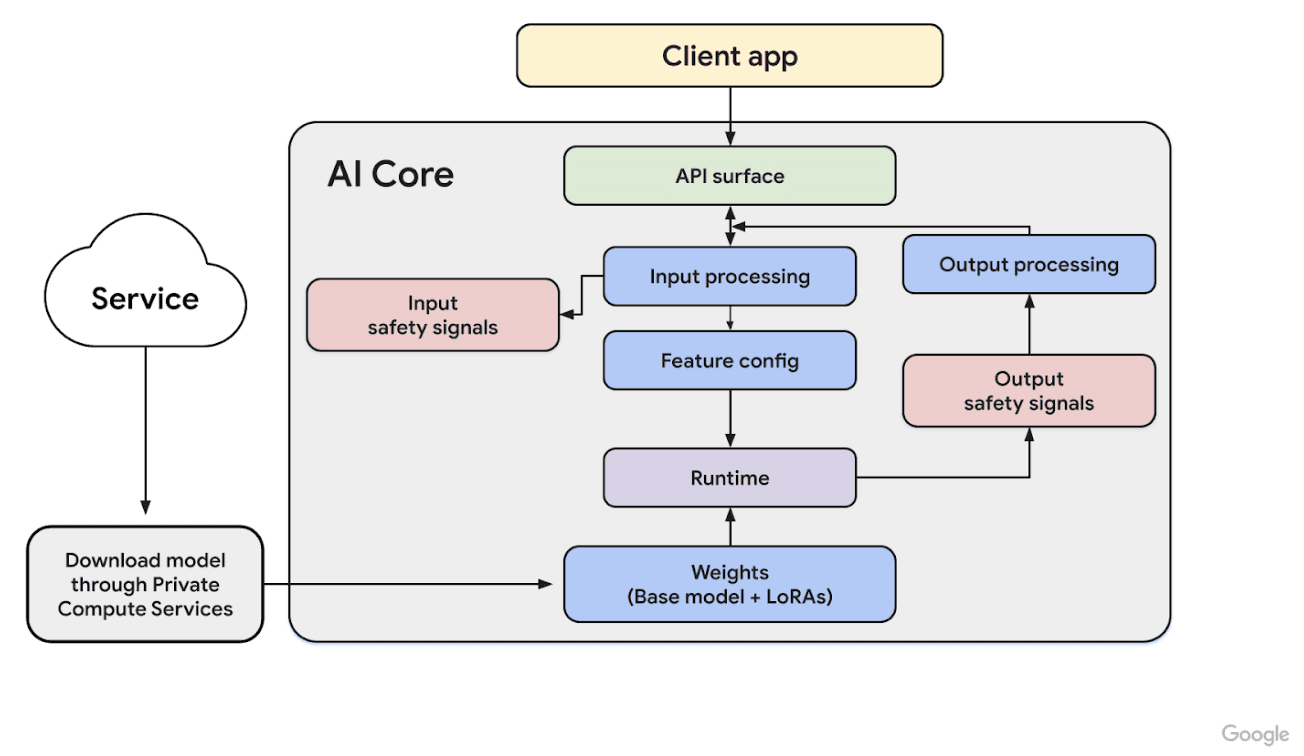
AI Core Architecture Diagram
Now that we understand roughly how it works, let’s dive in.
Hands On
If you try to launch that sample app without meeting the prerequisites, you’ll get this error message.
Failed to check model availability.
com.google.ai.edge.aicore.UnknownException: AICore failed with error type 2-INFERENCE_ERROR and error code 8-NOT_AVAILABLE:
Required LLM feature not foundThen, after updating the AICore, the Private Compute Services apps, and opening that sample app again, you should see in the logs that the model starts downloading:
com.google.ai.edge.aicore.demo D Downloading model: 3063135863 bytes
com.google.ai.edge.aicore.demo D Downloaded 132720 bytes
com.google.ai.edge.aicore.demo D Downloaded 2090361 bytes
com.google.ai.edge.aicore.demo D Downloaded 2090645 bytes
...
com.google.ai.edge.aicore.demo D Downloaded 4358020858 bytes
com.google.ai.edge.aicore.demo D Download completed.So the model is around 2.8 GB, but there’s more being downloaded, I hooked it to GlassWire and saw this.
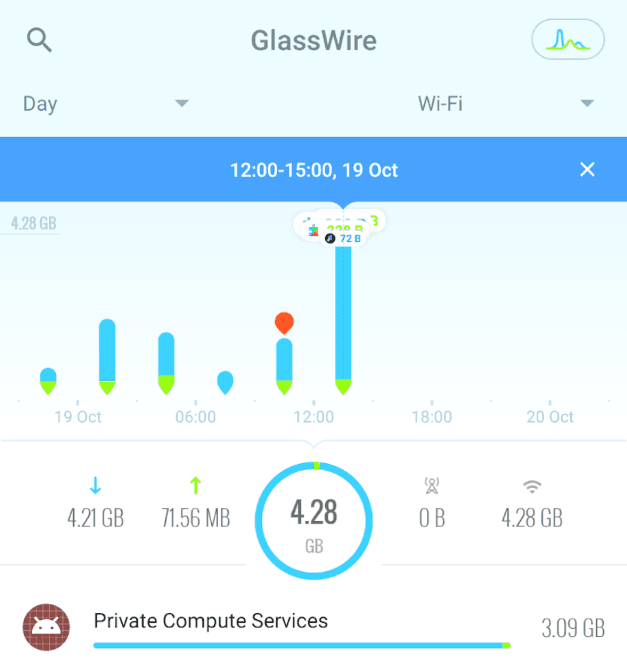
GlassWire Network Monitor
It shows that just over 3 GB of data was downloaded using Private Compute Services, as they promised they would. Then, checking my AICore App, I you can see that it’s now taking around 4.3 GB of what is probably the uncompressed model + weights.
The bottom line here is that a minimum of 4.3 GB of local storage is going to be required for this to work.
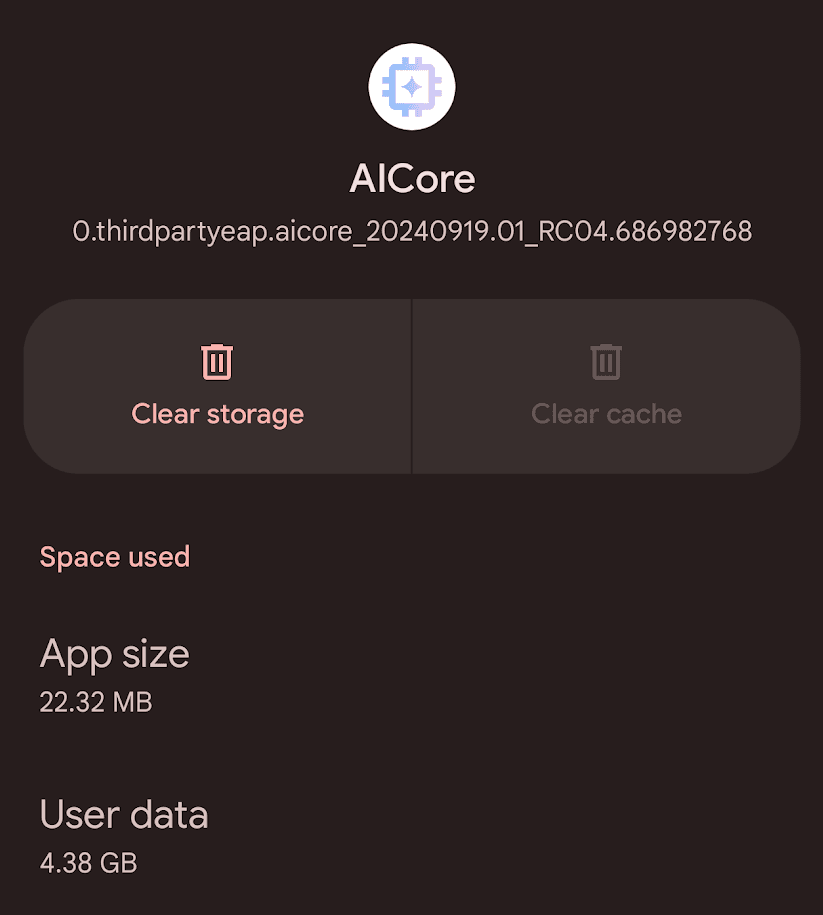
AICore Storage Usage
Show me the code already
For something so “exciting” the code you need for using is a bit underwhelming. I mean, it’s very basic. There are just a couple of things you need to do to make this smoother for the user.
The main object is the GenerativeModel. It takes two parameters: DownloadConfig and GenerationConfig.
GenerationConfig is where you define the main settings, like maxTokens, temperature, etc. These parameters are standard across LLM models and frameworks, so I’ll leave them out of this article’s scope. A quick Google search should get you in a good place.
Putting things together we get:
val downloadConfig = DownloadConfig(
object : DownloadCallback {
override fun onDownloadStarted(bytesToDownload: Long) {}
override fun onDownloadFailed(failureStatus: String, e: GenerativeAIException) {}
override fun onDownloadProgress(totalBytesDownloaded: Long) {}
override fun onDownloadCompleted() {}
}
)
private val model = GenerativeModel(
generationConfig = generationConfig {
context = applicationContext
maxOutputTokens = 600
temperature = 0.9f
topK = 16
topP = 0.1f
},
downloadConfig = downloadConfig
)This is it. Some weird parameters, but that’s all there is to it. Now, before we’re good to go we need ensure the model is ready to use. Checking things like:
- Is this a compatible device?
- Is the model downloaded?
To do that, we can call the prepareInferenceEngine and handle the exceptions.
runCatching {
model.prepareInferenceEngine()
}.onFailure { e: GenerativeAIException ->
Log.e("TAG","Model not available: ${e.message}")
}Finally, you can generate the response synchronously.
val response = model.generateContent(input.buildPrompt())Or do it asynchronously; for simplicity, I’m just appending the newly generated text as it’s being streamed, like so:
var result = ""
val job = scope.launch {
model.generateContentStream(input.buildPrompt())
.collect { responseChunck ->
result += responseChunck.text
println(result)
}
}
// Which you can cancel midway
job.cancel()Now that’s it. If you run that code, Gemini will start streaming down text. That is of course, if you ask it nicely. What do you mean nicely? Well… it’s complicated.
Mic check, 1,2… is this thing on?
You see, I think it’s fair to say that most of things you’ll try with work straight away, but it’s likely you’ll hit some snags on the way. Eg.:
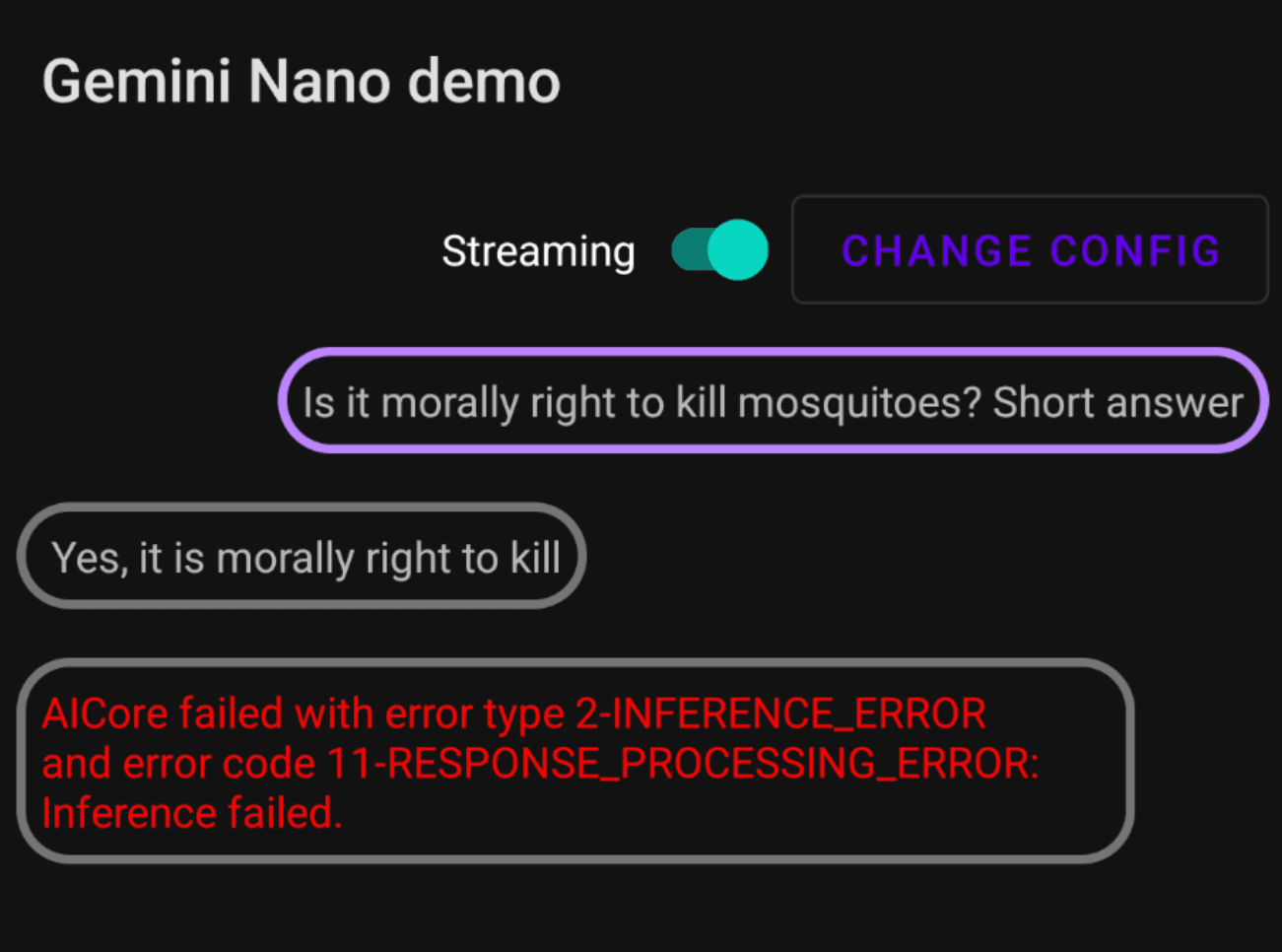
✋ Stop! We don’t do that here.
It’s unclear what exactly is considered out of bounds, and I think they’re being very conservative with these settings, which is likely to avoid some PR disaster. For an experimental product, I think that’s fair.
If you do ask it nicely, then I have to say that it’s pretty fast! Especially if you remember that this is the worst it’s ever going to be.
Apart from security, you’ll notice another an issue when you start testing the limits of its Context Window The Context Window of an LLM refers to the amount of text in tokens that the model can consider in one go when making predictions or generating text. The larger the context window, the more text the model can consider, which often leads to a better understanding of context and more coherent responses. Although there’s a counter argument. There is a tradeoff between the context window and computational resources. Larger windows demand more memory and processing power.Context Window
First of all, I couldn’t find any explicit information about Nano’s context window size. In the paper, they say that the models support a 32k context window, but I assume that’s obviously not the case for Nano running on a phone.
Now, the paper also says that Nano is a 4 bit quantized Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like int8 instead of the usual float32. Think Pros: Cons:Quantization
wav -> mp3.
Back of the napkin estimation - don’t take this seriously!
3.25B × 4 bits = 13 billion bits = ~1.625GB for model weights.
Given we have 3GB of RAM available, that means we need to stay within 1.375GB.
I did some research and an uninformed estimate could gives us between 2048 and 4096 tokens.
Empirical trials
Or Throwing things at it and seeing what sticks.
I prompted it with an excerpt of 4k tokens from the Gemini paper to ask questions about it. It worked reasonably well. For reference, ~4k tokens is what you read from the beginning of the article until here.
Then, I tried increasing that to around 7k tokens by adding excerpts from another paper and it started logging some weird errors, and I couldn’t get it to answer it. Finally, I tried duplicating the original prompt, getting close to about 10k tokens and it worked(?)! Though it took way longer.
As you can see, my math was off (as usual), but so were the docs and the error messages. Actually, that’s another big pain point when working with this, but at least they’re aware of it.
AiCoreInferenceHelper
com.google.android.apps.aicore.base.InferenceException: null (statusCode = 4)
at biw.a(PG:1049)
at dgx.a(PG:13)
at duz.g(PG:3)
at dvb.run(PG:42)
at cou.run(PG:3)
at dsl.run(PG:50)
at amg.run(PG:50)These are not super helpful. The internal components (things inside com.google.android.gms.internal.aicore) are obfuscated, so the SDK really works like a black box, which is somewhat expected since LLMs are, by definition, black boxes. Though, I’d like to see better API documentation, including the recommended context window size and information on performance degradation for larger contexts.
Making it smarter
Not gonna lie. Nano is not the smartest kid in the room, and it shows. The main problem is that On-device models have some hard constraints, like the limited parameter size and smaller context windows.
To improve their performance we can use fine tuning. Or more specifically, LoRA Low-Rank Adaptation (LoRA) is a technique designed to refine and optimise large language models. Unlike traditional fine-tuning methods that require extensive retraining of the entire model, LoRA focuses on adapting only specific parts of the neural network. This approach allows for targeted improvements without the need for comprehensive retraining, which can be time-consuming and resource-intensive.LoRA (Low-Rank Adaptation)
Efficiency Example
Press X to doubt
It’s no doubt that things are still very rough around the edges. You can certainly build products with it, like Google and other OEMS are doing, but there’s a few blockers that we can need point out:
Device support: Just a few devices currently have the hardware to support this and those are top of the line ones. Android is known for cheaper models which make it ideal for users on a budget (most people). It’s still unclear to me how well the new hardware and increased memory requirements are going to rollout to these cheaper devices or how long would that process take.
Base models lower quality: LoRA can help, but Nano is still not going to match what you can do with the models running on the cloud which limits the use cases a lot.

‘This ain’t going nowhere’
It’s a movie, not a picture
Now, the counter argument to that is that while those points are true, we need to understand how this environment is playing out.
For example, what are some of the core constraints:
- Compute: How hard we train each generation of models.
- Parameter size and training data: More parameters generally mean that the model have a better understanding of the input, and more training data gives it a better understanding of how different concepts relate to each other in meaningful ways.
Despite all the valid criticisms you can have, what’s happening in AI right now is nothing short of absurd. This stuff puts Moore’s Law to shame. Doubling the number of transistors in a chip every 18 months? Neah… how about a 10 fold improvement over these core constraints every 12 months?

Training compute (FLOP) used over time
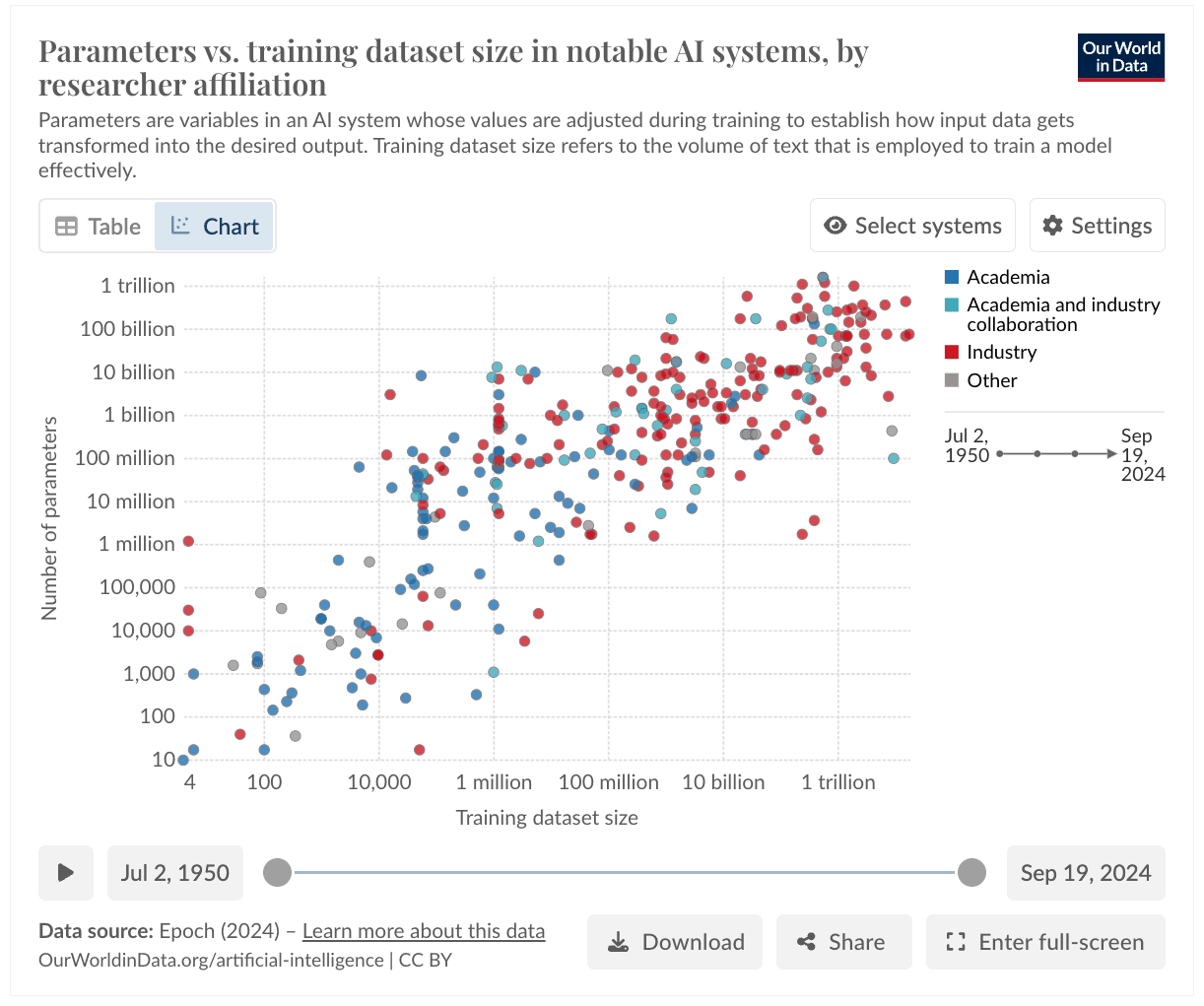
Parameter vs training dataset size
There’s a counter argument to these graphs, which say that we may run out of data before to train them soon. However, if you connect the dots with what Google specifically is doing for this to work on Mobile, then you start getting where this is still likely going. Just look at this.
](/static/ad52f69610f6090af2e4d35a069e3aba/813c5/local-llm-evolution.png)
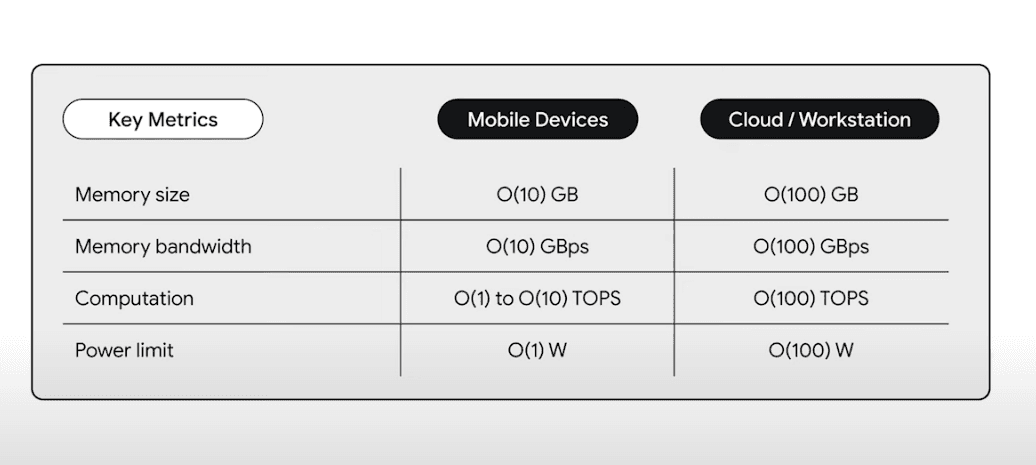
Mobile = ~Cloud/10
Mobile hardware constraints are about 2 orders of magnitude from the workstations or the cloud and judging from the data above it starts looking clear that it’s a matter of time before local models are just as capable as the current generation of cloud models.
Look, I’m not making any claims about AGI or AI improving exponentially forever. I’m just pointing out that what we can do in the cloud now, will be feasible on devices soon, which I think it’s reasonable and backed by the data.
Building for the future
Now, if you’re convinced that all of this makes sense and you’re interested in building something what to do now? Should you get a new device just for that?
Well, I don’t think so. At least not yet. The AIEdge SDK is still experimental and supported on just a few devices, so I recommend another way of going about this.
In my opinion, at least so far, Google has adopted what it looks like a very coherent approach for their AI dev tools. The APIs are very similar and there’s options for gradually going up the ladder of investment. Just look how similar they are.
AI Edge SDK
import com.google.ai.edge.aicore.GenerativeModel
import com.google.ai.edge.aicore.generationConfig
private val model = GenerativeModel(
generationConfig = generationConfig {
context = applicationContext
maxOutputTokens = 600
temperature = 0.9f
topK = 16
topP = 0.1f
}
)
val response = model.generateContentStream(input.buildPrompt())Google Generative AI SDK
import com.google.ai.client.generativeai.GenerativeModel
import com.google.ai.client.generativeai.type.generationConfig
val generativeModel = GenerativeModel(
modelName = "gemini-flash-1.5",
apiKey = BuildConfig.GEMINI_API_KEY,
generationConfig = generationConfig {
maxOutputTokens = 600
temperature = 0.9f
topK = 16
topP = 0.1f
}
)
val response = model.generateContentStream(input.buildPrompt())Firebase with Vertex AI
import com.google.firebase.vertexai.GenerativeModel
import com.google.firebase.vertexai.type.generationConfig
val model = Firebase.vertexAI.generativeModel(
modelName = "gemini-1.5-flash",
generationConfig = generationConfig {
maxOutputTokens = 600
temperature = 0.9f
topK = 16
topP = 0.1f
}
)
val response = model.generateContent(input.buildPrompt())Moving from one to another is almost as easy as changing the imports.
So I think a good game plan would be to validate your AI feature idea using AI Studio. If that works, then you can prototype it with the Generative AI SDK. If you’re confident that it can be shipped, roll it out to your users (probably A/B testing) using Firebase with Vertex AI.
If you get positive feedback and you think price will be a problem, or rather, if the AI input data is privacy-sensitive, then you can try your chances with the AIEdge SDK.
Wrapping up
The article stretched out more than planned, but if you’re still here, you’re either really into this or just jumped to the conclusion. In any case, the bottomline is that rate of improvement is significant enough that local models could be 12-18 months away from being capable of handling many use cases locally. You can start thinking about it or even start building now.
If you’re interested, you can read this three-part series on Prototyping an AI App, where I documented my process.
We’re not there yet, but in my opinion this is a preview of what will likely become a standard capability of future apps. Just like GPS, Bluetooth, or NFC, many apps will build on this. Not every app will need it, just as not all apps require GPS or Bluetooth, but certainly, many will. You can read some more thoughts about that
What’s next?
There’s yet another SDK for LLM inference on Android that, as pointed out by Paul, I have not talked about. It’s the MediaPipe LLM Inference API and hope to play with that in the near future.
For now, I want to get some hands-on experience with LoRA and how to apply to Gemini Nano. So you can expect an article on that soon.
Besides that, earlier this year I’ve pushed a container to GCP with a Python backend and a very basic RAG implementation using Vertex AI and LangChain. Now that Gemini 1.5 is out, I need to try it with the new 1MI or 2MI tokens context window options and eventually hook it up with my AudioGuide AI App I built last year. Let’s see if can put those together.
I’ll keep you posted either way. Cheers!