The First Way
Automating the Value Stream to Solve "It Works on My Machine" Issues and Improve Code Quality.

The First Way of DevOps: Automating our Value Stream
Have you ever heard the phrase “it works on my machine”? It’s one of the biggest pain points for any software development team. But what if I told you that there’s a way to solve it? That’s where the First Way of DevOps comes in.
The idea behind the First Way is simple: by identifying, measuring, and improving the flow of work through our value stream, we can optimize and refine the ability to deliver value to our customers.
Let’s start with pipelines
You’re probably already using a build system to automate some parts of our value stream, but we can do better. Quoting from the Devops Handbook:
In order to create fast and reliable flow from Dev to Ops, we must ensure that we always use production-like environments at every stage of the value stream. Furthermore, these environments must be created in an automated manner, ideally on demand from scripts and configuration information stored in version control, and entirely self-serviced, without any manual work required from Operations. Our goal is to ensure that we can ** re-create** the entire production environment based on what’s in version control.
The authors go on to say that we should enable on demand creation of dev, test, and production environments so developers can run production-like environments anywhere, even on their own computers, created on demand and self-serviced.
This way, developers can run and test their code in a production-like environment as part of their daily work, providing early and constant feedback on code quality.
We’ve all been there before:

The “It works on my machine!” issue comes from the fact that in any complex system there’s just too many variables to manage. If you google The Matrix of Hell you’ll might see something like this:
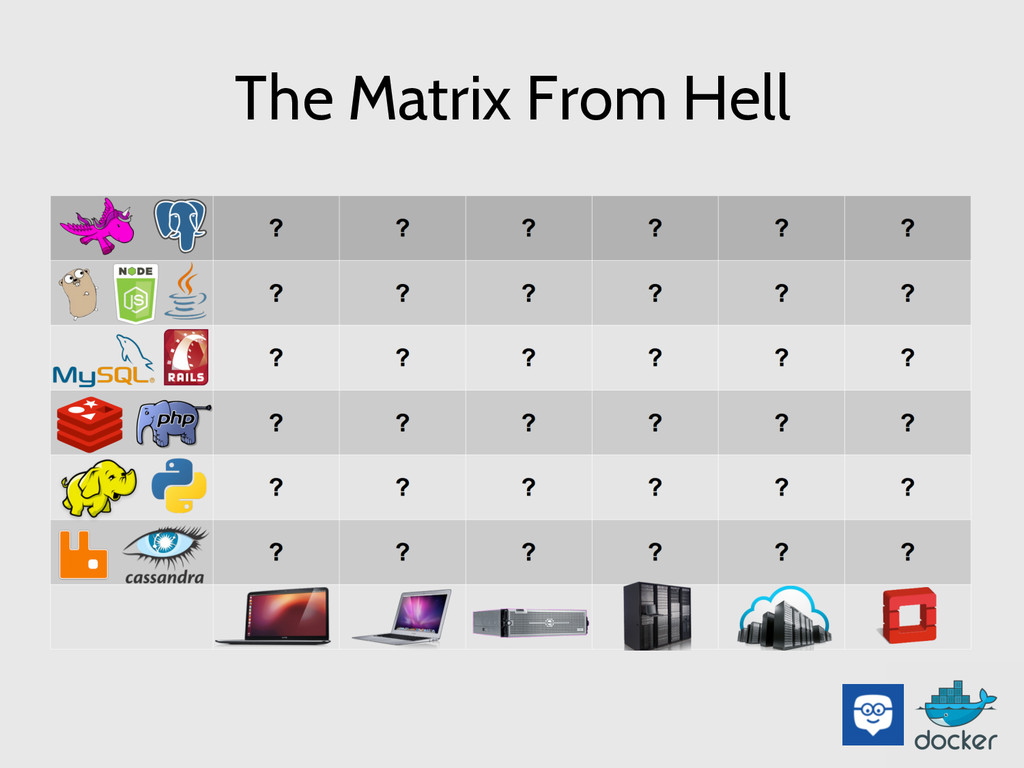
Different kind of applications will have different rows and columns in this table, but you get the idea: - Multiple environments with multiple third party dependencies, create a combinatorial explosion that no sane human being can manage.
Most companies will have a test and production environments, maybe you even have a dev environment where you can safely run your app with the hottest new features. But as the project evolves, non-production environments tend to degrade. It’s hard for them to keep up with prod because of lack of automation or the discipline of constantly updating it. After a while the dev environment will have so many small things that work differently that it becomes hard to trust it. Some months down the line and people will stop believing anything that happens in the dev environment and only newcomers, still unaware of these issues, will be using it at all.
How to fix that?
The issue is that if these environments were manually created, you can’t expect people to maintain them equally. By automating their creation we enable anyone to quickly spin up a new environment on demand, enabling every developer to have their own local environment when they need one. The automation scripts will make sure that the correct configuration is loaded on each environment, avoiding hundreds or thousands of hours of unneeded headaches over a misconfiguration due to human error.
This way we’re effectively giving the development team access to production-like environments by treating your infrastructure and configuration as code, making immutable infrastructure, ensuring where we operate, develop, and test is comparable and a reliable indicator of system operation for customers — such that new value contributed by developers can easily and predictably be deployed to customers.
It’s hard, but it pays in the long run!

This is not a simple issue to solve. And you should be mindful about when and where to start the process.
In my experience, small startups or software studios tend to overlook this, because it’s too much to worry about this stuff at their product stage.
If your project doesn’t have to scale, fine. You can get away from following these ideas in smaller projects, but the engineering team has to stay vigilant for when they should stop and implement a solution.
If you get big enough the cost of not having on-demand, dev/prod environment parity will also scale, even faster than your product. And hiring more people will only make the cost increase. Hundreds or thousands of development hours go down the drain because of this issue. Bugs that are impossible to reproduce make debugging even harder, fear of changing “buggy” parts of the application causes code quality to suffer and everybody suffers.
Every team and organization is different and deciding when to start with this approach has to made in case by case scenario, but I’d argue that it’s certainly cost-effective to gradually implement this idea in the early stages of a project.
Create our single source of truth for the entire system
To ensure that we can restore production service repeatedly and predictably (and, ideally, quickly) even when catastrophic events occur, we must check in all the assets needed to recreate the system state.
That includes:
- All application code and dependencies (e.g., libraries, static content, etc.)
- Any script used to create database schemas, application reference data, etc.
- All the environment creation tools and artifacts
- Any file used to create containers (e.g., Docker or composition files)
- All supporting automated tests and any manual test scripts
Ideally this should happen using immutable infrastructure where no manual changes occur - make it easier to destroy and rebuild than to configure.
Encoding knowledge and sharing it through a repository is one of the powerful mechanism for propagating knowledge. Particularly when it includes every library (internal or external), and those each have an owner responsible for ensuring it successfully passes all tests.
Wrapping up
We’ve seen how dev/prod parity begets automation. If you’re not yet embracing these concepts, well, you quite frankly should, or at least be aware of the issues that are coming your way. But fret not! We’ve all been there and those who came out alive have some very interesting ideas about how to solve it. We just have to listen to them.