Running on the Edge: What, why and how
Alternatives for running On-device AI on Android

I recently gave a talk about Running LLMs locally on Android at the GDG Berlin Android, and I thought it would be useful to break it down into an article. This article breaks down what ‘Running an LLM on the Edge’ means, why you’d consider it for Android apps, and explores the current options available.
Edge Inference
An LLM is basically a large file containing learned language patterns represented as numbers. Running an LLM is often called inference. That just means we’re actively calculating and predicting the output based on its learned internal model. That is: performing statistical inference.
To run an LLM your text prompt is converted into number tokens, fed into the model which calculates the most likely next token. This process repeats, using the newly generated token as part of the input for the next step, allowing the model to generate (hopefully coherent) text. That’s why they call them autoregressive models.
So, when you run an LLM locally, you’re essentially using a program to perform these tokenization, calculation, and step-by-step prediction steps using that massive model file stored on your machine. It gets complex under the hood, but the core idea is just that: predict the next piece of text based on what came before.
You can get a bit more of the intuition what that looks like when using the transformers library to run Gemma3. If you find that confusing, don’t worry. We can go up another abstraction layer.
Probably the most famous open source inference engine is the llama.cpp. There are alternatives, and even abstractions built on top of it like the ollama project, which makes running an LLM as easy as:
❯ ollama run gemma3:27b
>>> Send a message (/? for help)So that’s Inference. What about Edge? Well, that’s just means the consumer hardware. Your laptop or your phone.
Ok, with this new knowledge we can reinterpret the article’s title. It’s about what are the alternatives for Inference Engines on Android.
But y tho?
Weren’t LLMs Super Hardware Intensive?
That’s one of the questions that can pop up. We hear about LLMs needing data centers full of GPUs, so running them on a phone sounds… ambitious. Plus, we already have powerful options like ChatGPT and Gemini available in the cloud. Why go through the hassle of running them locally?
Well, there are some reasons:
- Cost: Cloud LLM APIs often charge per token (input and output). If your feature gets popular, those costs can skyrocket. Running on-device means the inference cost is essentially offloaded to the user’s hardware (the edge), potentially saving you a lot.
- Latency: Calling a cloud API involves network roundtrips. On-device inference can be significantly faster, leading to a much snappier user experience.
- Privacy: This is a big one. If your app deals with sensitive user data (think personal messages, health info, finances), sending it to a third-party cloud might be a non-starter. On-device processing keeps that data on the user’s phone.
- Offline Availability: Self explanatory.
Buried in the AI News Hype Cycle:
When we talk about AI breakthroughs, the news usually focuses on the massive, state-of-the-art (SOTA) or frontier models. These are the Geminis, Claudes, Deepseeks and GPT-4s of the world. They crush benchmarks every week and dominate the headlines. But they’re just the tip of the iceberg.

LLM iceberg with SOTA models
But beneath the surface, something else is happening.

Efficient small models
There’s a fast growing category of smaller, highly efficient, and often open-source models. I like to call these the “Top Left Corner” models because when you plot performance against resource usage (GPU requirements or size), they show up on that top-left spot: high performance with low resource needs.
These models are catching up fast. Models like Mistral 24b, Llama 3.1, and Google’s own Gemma3 family are hitting benchmarks today that were SOTA just 6-12 months ago. Benchmarks show these smaller models achieving performance levels comparable to much larger models from just 6-12 months prior, often on significantly less demanding hardware. Think about that for a second. Models that can run on consumer hardware right now are just as capable as huge models were just last year.
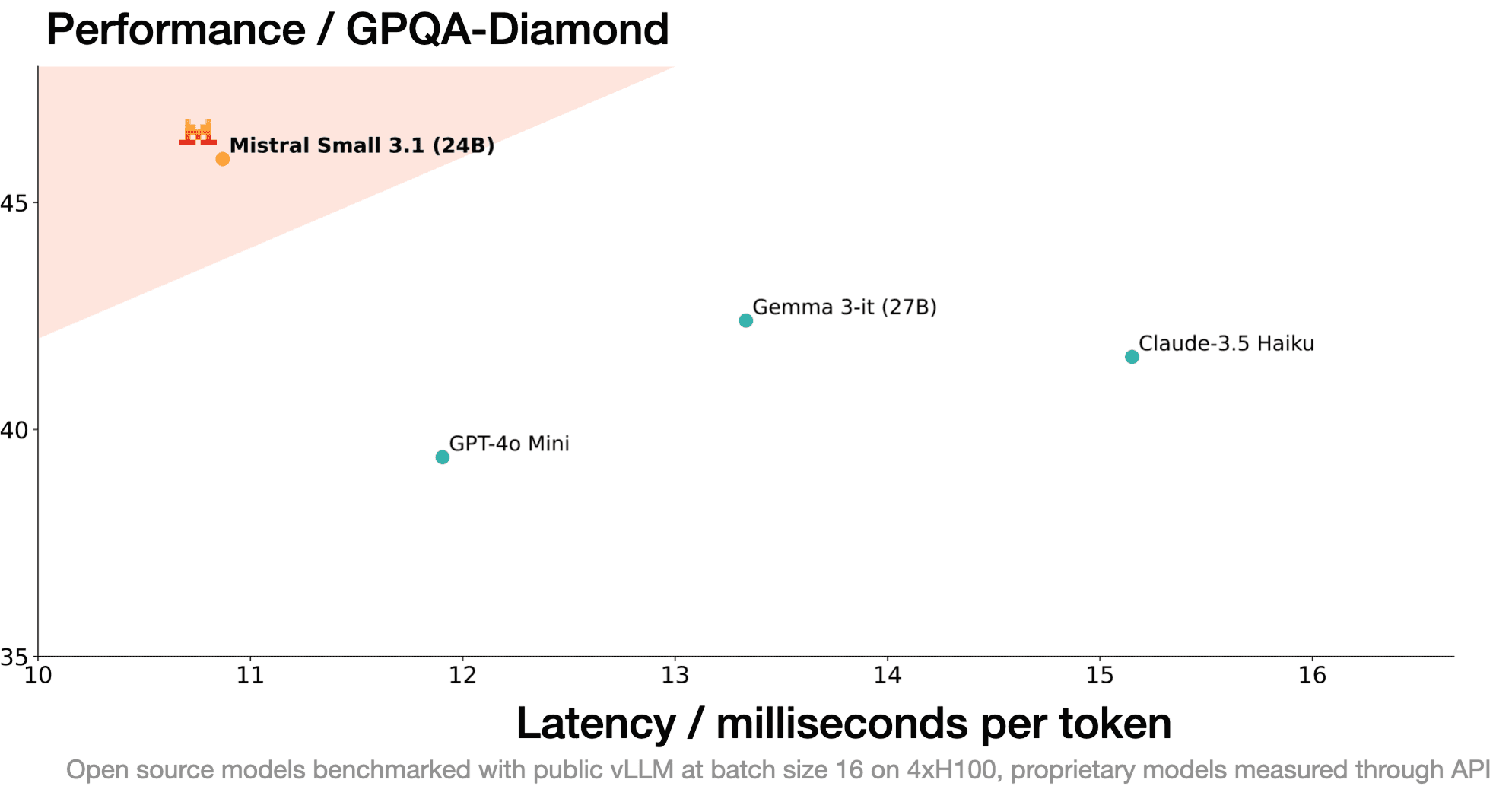
Mistral 24b latency results
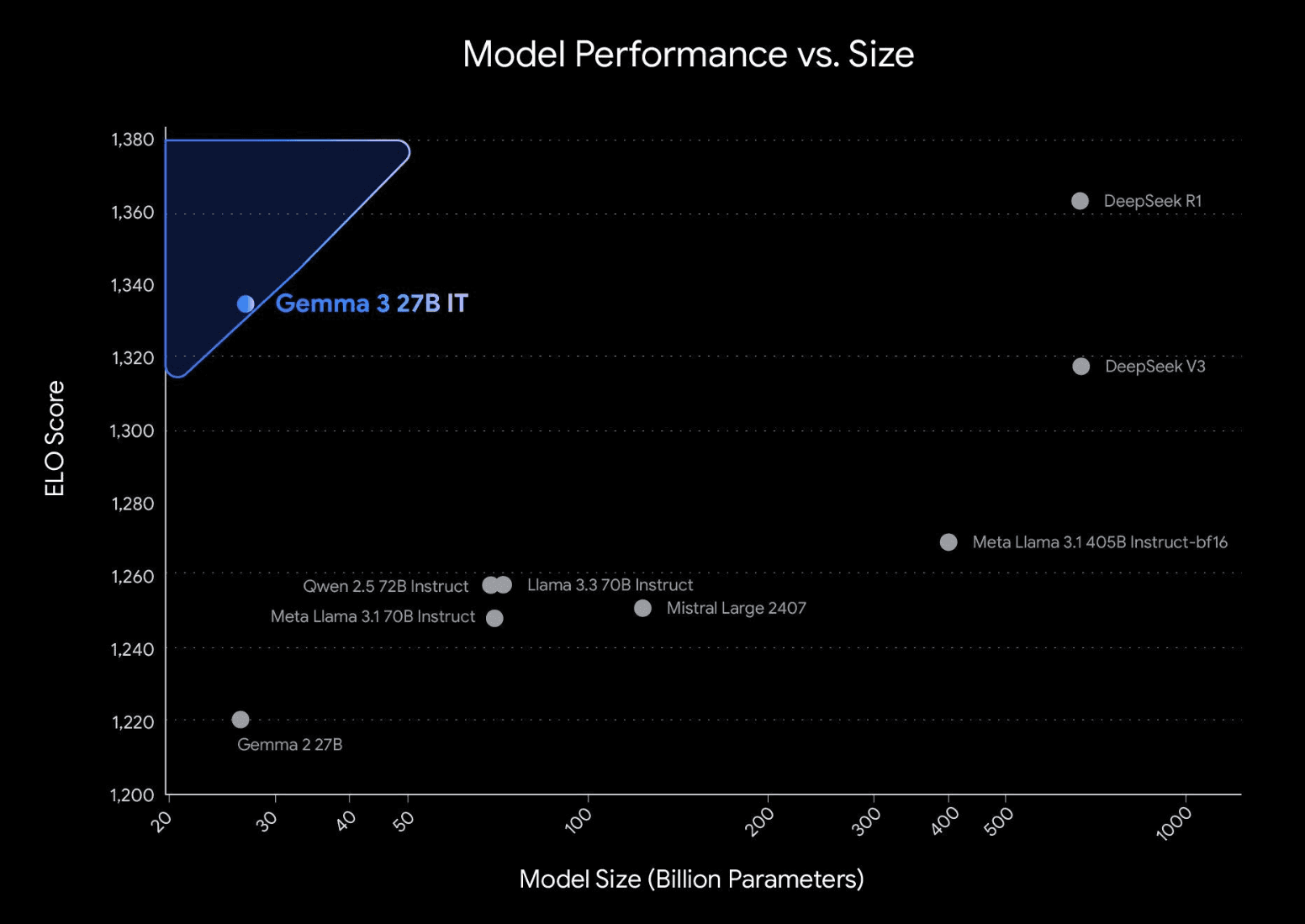
Gemma3 ELO Score vs Size
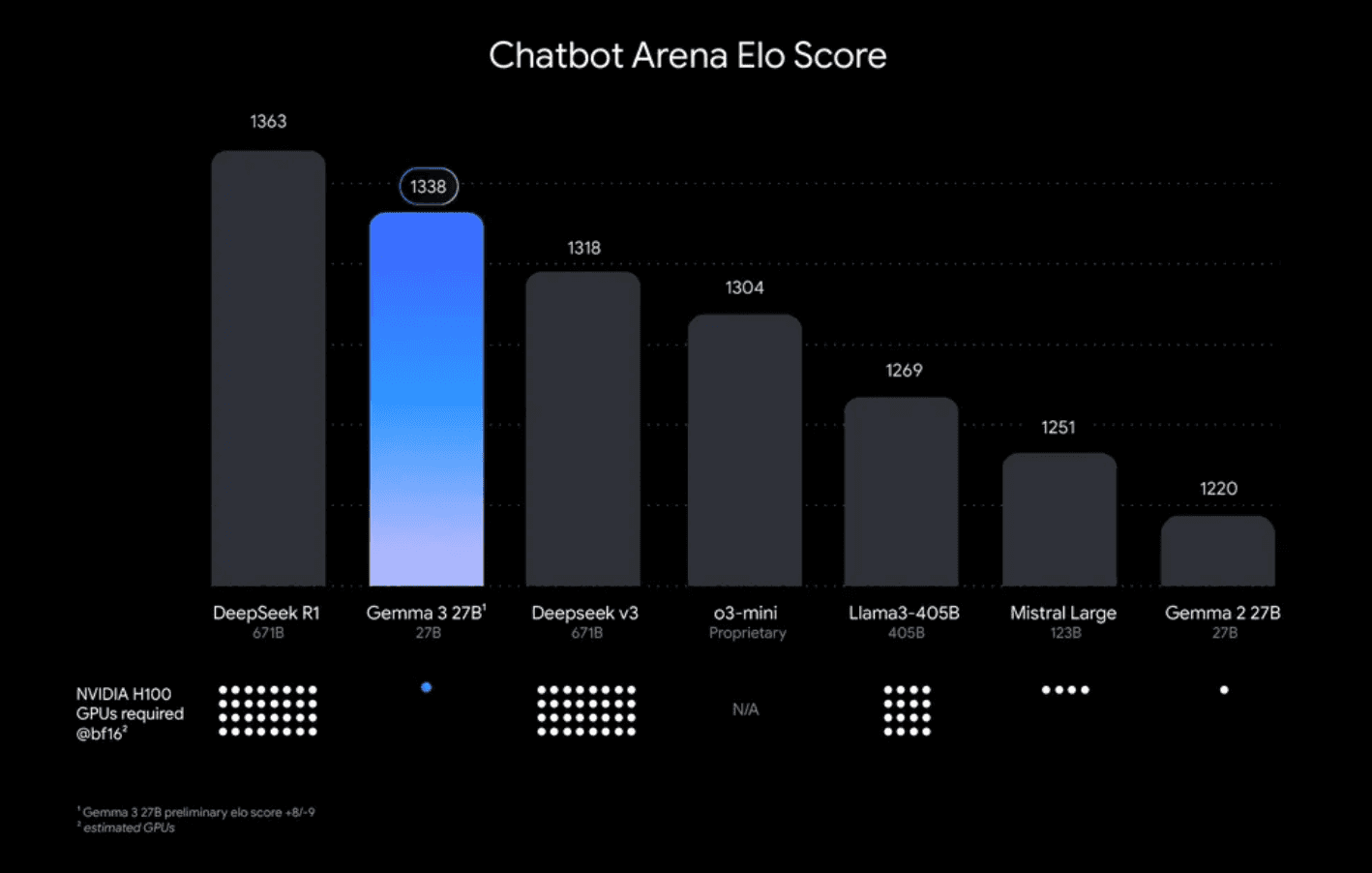
Gemma3 ELO Score vs GPU requirments
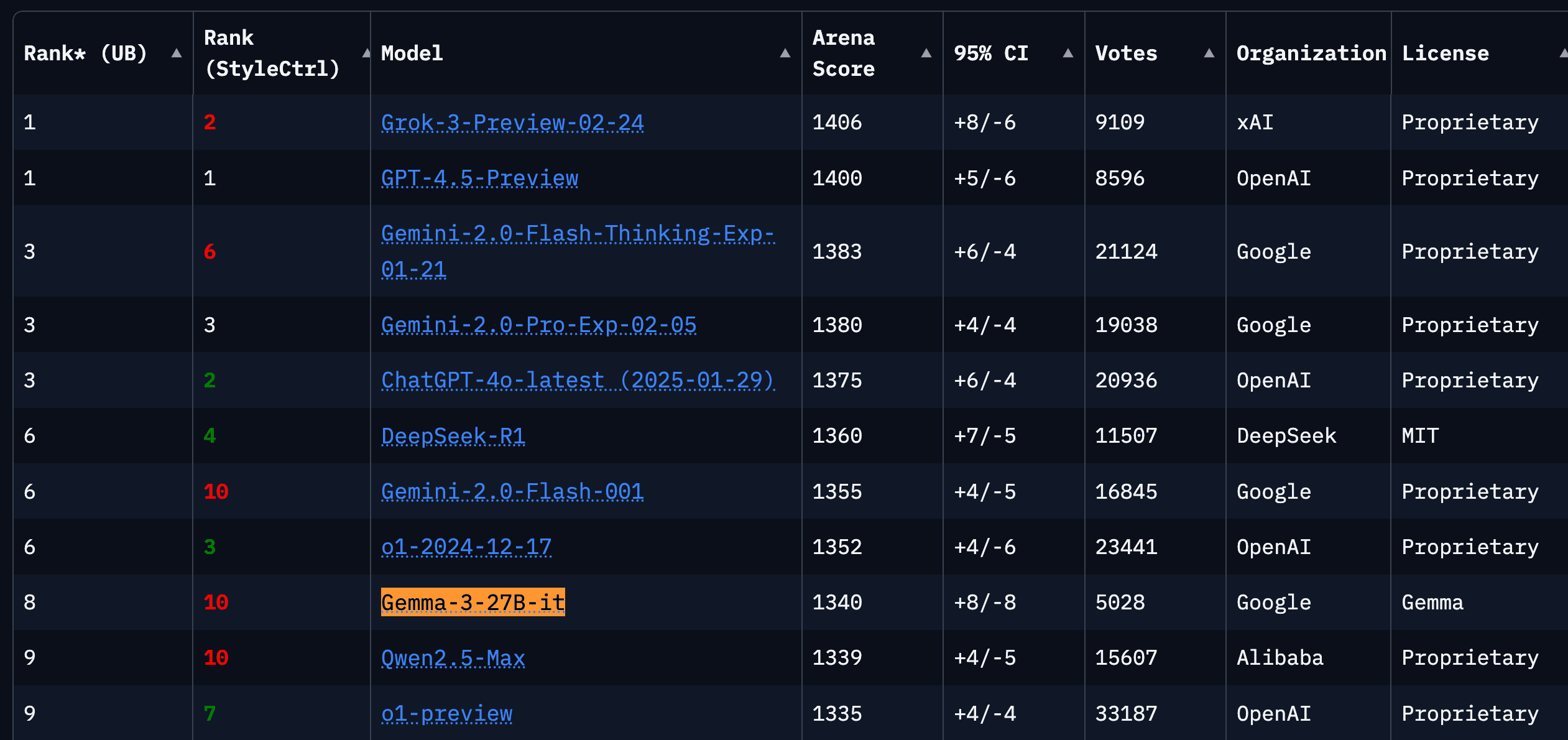
Gemma ranking on lmarena.ai
And importantly, some of these are efficient enough to run locally, even on mobile hardware.
Your Options for On-Device Android AI
Okay, if I this your attentionc, then you might be wondering how to do that. How to run LLMs on a device? Right now, there are essentially two officially supported paths for integrating on-device Generative AI into your Android app:
1. The System-Wide Approach: Google AI Edge SDK
This is Google’s integrated solution, designed to be the easiest path for developers. It leverages components built directly into the Android platform on compatible devices.
- Pros:
- Simple API, very similar to other Google AI SDKs (Vertex AI, Generative AI SDK).
- Platform handles model downloads, updates, and hardware optimization.
- Built-in safety features.
- Supports LoRA adapters for efficient fine-tuning.
- Cons:
- Limited Device Support: Currently only available on select high-end devices (Pixel 8/9 series, some flagship Samsungs).
- Significant Storage: Requires specific AICore and PCS APKs to be installed and updated, and the base Gemini Nano model takes up ~4.3GB of storage before any LoRA adapters.
- Model Choice: You’re currently limited to using Google’s Gemini Nano model provided by the platform.
2. The Self-Managed Approach: MediaPipe LLM Inference API
This option gives you more control and flexibility but also puts more responsibility on your app. MediaPipe is Google’s broader framework for on-device ML pipelines (vision, audio, text).
- Pros:
- Wider Device Compatibility: Doesn’t rely on AICore/PCS, so it can run on many more Android devices (even on iOS).
- Model Flexibility: You can run almost any text-to-text LLM, provided you can convert it to a supported format and the device has the enough resources (more on that later).
- Full Control: Bring your own base model, your own fine-tuned model (supports LoRA).
- Cons:
- App Handles Everything: Your app is responsible for downloading the model, managing updates, initializing the inference engine, and managing resources (memory!).
- More Involved: Requires a bit more understanding of ML concepts and model formats.
- Potential Quality/Size Constraints: You need to choose models small and efficient enough to run well on target devices.
- No Built-in Safety (from the API): You might need to implement safety filters yourself if required.
Gotchas and Limitations
Whichever path you choose, be aware of some current realities:
- Fine-tuning is Likely Needed: Base open-source small models can be quite “raw” or generic. You’ll likely need to fine-tune them (using LoRA or other methods) for your specific task to get good results.
- Hardware Requirements: These models still need significant resources:
- Space: As we saw, the AI Core APK takes over 4GB just for the base model. Self-managed models vary, but even smaller ones are hundreds of MBs or several GBs.
- RAM: Inference, especially with larger context windows, consumes a lot of RAM.
- Processing Power: While optimized, inference still needs decent CPU/GPU/NPU power for acceptable speeds.
- Context Window Limitations: On-device models typically have smaller context windows than the big cloud ones. Passing too much text (long conversations) will lead to signifcant performance degradation.
- Narrow Use Cases: Current on-device capabilities are good at tasks like text rephrasing, smart reply, proofreading, and summarization. More complex reasoning or generation is still challenging for the smaller models (though fine tuning can help a lot)
Why Should We Care About This Now?
You might look at the limitations and think:
I can’t see these smalls beating cloud proprietary ones. Why bother?
And you’d be right. For now. History doesn’t repeat, but it often rhymes.
From Mainframes to the PC
Remember mainframes? Well, I haven’t seen one. But back in Uni I heard that those were huge supercomputers meant for serious work. They were the only thing that could run actually useful computer programs. It would take a dedicated refrigerated room with super expensive accessory hardware. And people could communicate with them via a terminal. A real terminal. Those had a keyboard and a screen, mainly handling input/output for the central machine.
In the early days of computing, with the advent of interactive computing, the prevailing model involved a central computer connected to multiple terminals. This configuration, known as the centralized or mainframe model, featured a powerful central computer that performed all the processing tasks, while terminals served as input/output devices for users to interact with the system.

1970s-1980s mainframe computers

Computer terminal
Then came microcomputers, first seen as hobbyist toys on which one could play around, but not good enough for any serious work. We know how that turned out.
Early personal computer
Does that sound familiar?
I could go on and mention smartphones vs PCs and how there’s now a huge cohort of the population that uses these handhelds as their main computing device. Smartphones are still not faster than laptops or desktop computers, but they’re good enough for many people. You get the point.
The pace of improvement in AI, both in model capability per size and in hardware efficiency (TPUs/NPUs on chips), is incredibly fast. The gap between cloud and edge in some areas is shrinking fast. What seems like a “toy” or niche capability today could be a standard, expected feature on mid-range phones in 18 months.
So in my opinion, getting familiar with the concepts, APIs, and challenges now may pay off in the future. Besides, I’d argue it’s pretty fun to build with.
Getting Started
So, what’s the takeaway? While the AI Edge SDK offers the simplest integration, its device limitations are significant right now. The MediaPipe LLM Inference API offers broader compatibility and model choice but requires more heavy lifting from your app.
My recommendation?
- Prototype & Validate: Use tools like Google AI Studio or cloud APIs Vertex AI in Firebase, to validate your feature idea.
- Consider On-Device: If your feature requires privacy, offline use, low latency, or if cloud costs are a concern, then explore the on-device options.
- Choose Your Path:
- If targeting only the latest high-end Pixels/Samsungs is acceptable, AI Edge SDK is a good choice.
- If you need wider device reach today or want full control over the model, MediaPipe LLM Inference API is a route, but be prepared for the extra work of model management.
The “genie” of powerful AI is definitely starting to squeeze into the “bottle” of our mobile devices. It’s not fully comfortable in there just yet, but it’s making progress fast. IMO it’s an exciting time to be an Android developer and lead the way. Make no mistake, competition will soon innovate and make a huge fuss about this too.
Other Resources:
- Google AI Edge SDK Documentation (Official Docs)
- MediaPipe LLM Inference API (Official Docs)
Related articles:
- AI Edge SDK Overview
- Gemini On Android - The Story So Far
- Prototyping an AI APP Series. Parts 1, 2 and 3