Non-Deterministic Interfaces or How AI is Coming for the Frontend
The system is working correctly, it's just that 'correctly' now includes probability.

xkcd: Can’t wait to find the intersection of debugging and philosophy
Last month the Flutter team dropped a GenUI SDK. The idea is you register a widget library, give an LLM the component definitions and let it decide what to render and with what data.
At its core, the GenUI SDK for Flutter is an orchestration layer. This suite of packages coordinates the flow of information between your user, your Flutter widgets, and an AI agent, transforming text-based conversations into rich, interactive experiences.
And it’s not about Flutter. Vercel’s AI SDK first announced GenUI support back in March 2024. Google is experimenting with that on search and the Gemini App. They recently published this interesting paper on the topic.
Server-driven UI, but the server is now a language model. I don’t think this is particularly revolutionary as a concept, but IMO they’re signals.
Something’s cooking.
The chat interface ceiling
We’ve been interacting with LLMs through chat windows for a few years now. Text in, text out. Then we got multimodal input/output, but still very limiting. Markdown became the de facto UX improvement, and if you’re lucky you get a Mermaid diagram integration here and there.
It works. But it’s also obviously limiting. The LLMs already are good at generating structured information (structured output). Why are we constraining the output to a text box?
The logical next step is letting the model decide not just the content, but the presentation. Which components to render. How to lay them out. Based on the query, the context, whatever signals are available.
This isn’t a prediction. It’s already happening in various forms.
Take Claude Code’s AskUserQuestion tool. A criminally underrated feature (which every other agentic coding tool was quick to copy). It’s so simple and illustrates this idea well:
Instead of a lot of back and forth with the agent, I ask it to generate a multi-step wizard UI on the fly. Here’s a snippet of how I use it with a simple gemini-image-gen skill I built.
> [!IMPORTANT] YOU MUST USE AskUserQuestion tool for gathering user feedback before starting generation.
>
> - The questions should attempt to cover the parameter space for the given task. Identify the key dimensions, constraints, and optimization targets that a specialist would consider when creating such an image.
> - After gathering the feedback from the user you must launch another AskUserQuestion round, but this time offering suggestions that should attempt to offer enough variability to the output, but still adhering to the confirmed constraints. One of the suggestions should be a bit out of the box.What you get is this:
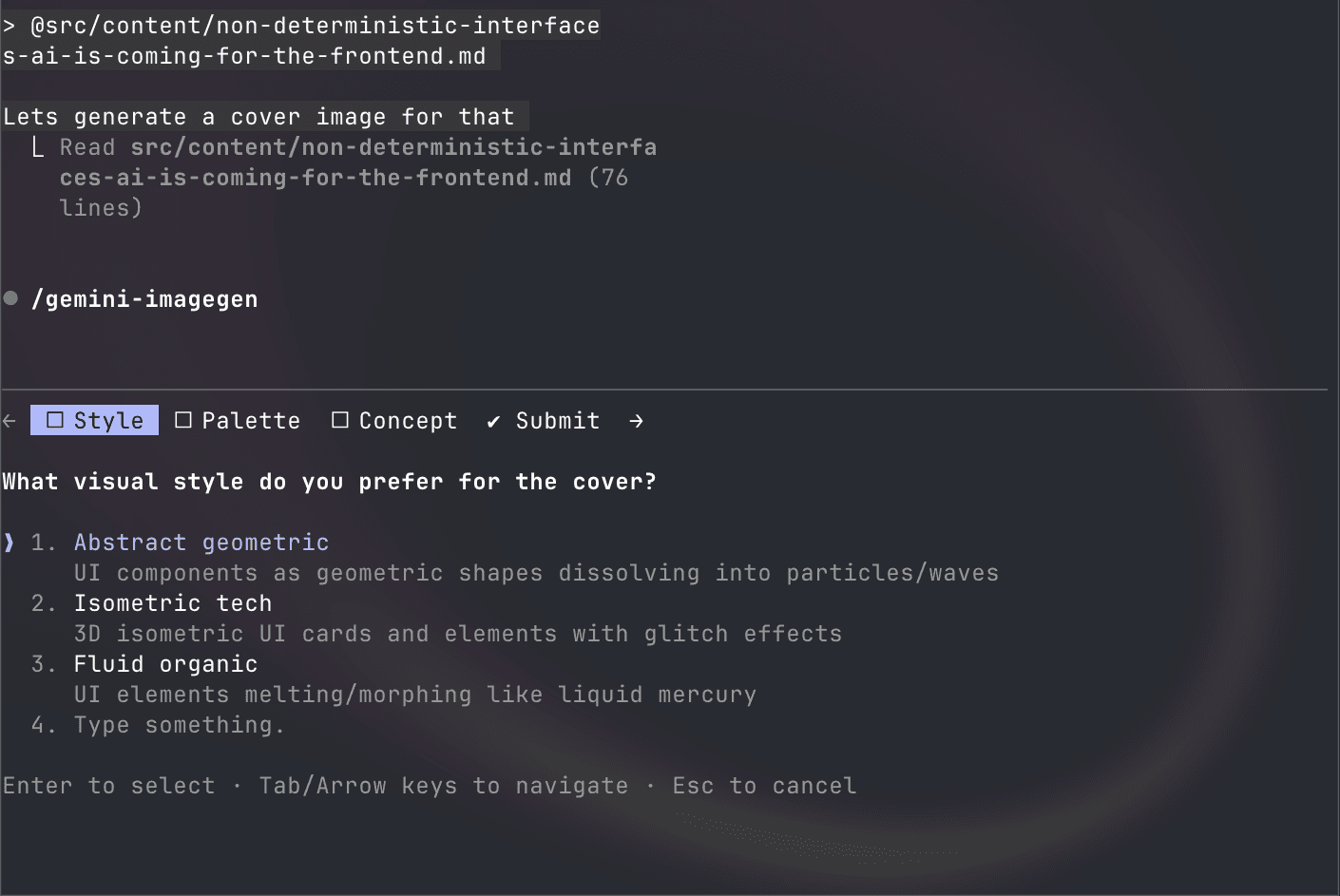
Claude Code’s AskUserQuestion tool generating a wizard UI for image creation
The AI reads the context (this blog post), then dynamically generates relevant style options, each with descriptions. A multi-step flow with Style → Palette → Concept → Submit.
No one coded this specific wizard. The structure emerged from the prompt and context. This is the whole idea in a nutshell.
What this actually means
Here’s the part that’s been rattling around in my head.
We’ve spent decades building (or attempting to build) deterministic systems. Same input, same output. That’s the contract. That’s what users expect. That’s what testing assumes.
Generative UI breaks that contract. Ask the same question twice, and you potentially get different layouts. Different component choices. Different emphasis. The system is working correctly. It’s just that “correctly” now includes probability.
And I think that’s… fine? For certain problems? Maybe?
LLMs work best when there’s no single correct answer. When the space is ambiguous. So that may work for a set of use cases.
The interesting bit
The implication is that we’ll have products where the interface itself is non-deterministic. Probabilistic by design.
That raises questions I don’t have answers to:
- How do you test this? Are we going to start benchmarking user satisfaction?
- What’s the fallback when the generated UI is wrong or confusing?
I suspect the patterns will involve things like user correction loops, graceful degradation to deterministic components, and some form of transparency about uncertainty. But the industry hasn’t figured this out yet. We’re in the “interesting problem” phase.
Not everything, obviously
Most apps don’t need this. CRUD with well-defined flows doesn’t benefit from probabilistic UI decisions. If you know exactly what the user needs to see, just show it.
But there’s a class of problems where this might make sense. Where the “right” UI genuinely depends on runtime context that’s hard to enumerate in advance.
The point isn’t that generative UI is the future of all frontends. The point is that it seems to have found a legitimate niche. And that niche implies a shift in how we think about building certain kinds of products.
The stack is splitting
There’s an interesting framing that’s been floating around that talks about how some software could be decoupled into three layers.
At the bottom, you have the system of record, your data models, APIs, etc. The durable stuff that doesn’t change much. Above that you’d have an agentic layer that would abstract the application logic and at the very end you would have a generative UI layer.
Pixels generated at runtime for a specific user and goal. A one-off chart. A temporary decision panel, etc.
The interesting implication: if the interface layer becomes ephemeral, in that scenario you would stop building screens and start curating component libraries that agents can assemble on demand. Weird.
Weird times
We’re quietly moving toward a world where some products are non-deterministic by design. And that is really weird.