Memory Portability: Owning what matters
Your AI memory is a huge liability. Don't leave it locked in a corporate silo.

What if your AI assistant could remember everything you’ve told it? Across sessions, across tools, across providers. Not locked into one company’s servers. Portable. Yours.
Why This Matters
I’m not sure who’s winning the LLM wars. But I know this:
If I’d been feeding ChatGPT my data for the past two or three years, you probably couldn’t pay me to switch now.
The more it knows you, the more indispensable it gets. The friction to change providers becomes enormous.
Sure, people stay with providers for other reasons: model quality, integrations, habit, pricing. But those factors shift. A better model launches. Prices drop. APIs get abstracted away. Memory is different. It compounds over time. The longer you use a system, the more context it accumulates, and the harder it becomes to replicate that elsewhere. That’s what makes it the stickiest form of lock-in. Almost like a natural monopoly.
The Manual Approach
I’ve been trying to maintain multiple system prompts: one for health data, one for financial context, some for general coding preferences. I share them across multiple providers/clients: Gemini, Claude, OpenAI, Msty Studio, Raycast, AI Studio, etc. Each context file gets tweaked over time as I learn what works and the data evolves.
It’s obviously tedious, but provides enough benefit that I keep doing it. Still, every time I switch tools or start fresh, I need to surface that context somehow. Each tool has a way to inject relevant context, and sometimes you just have to paste it. There’s gotta be a better way.
I remember reading about memory layer tools like Mem0 back in 2024. At the time it felt like too much work, maybe targeting devs building agents.
So I started thinking: what would a basic memory system look like? Something I could prototype using the hook system from my Shadow Claude project?
The Memory Model Basics
I sketched out what a minimal memory system would need. Two core flows:
Memory Storage
This summarizes what happened in a session: user preferences, decisions, facts. Vectorize for semantic search.
Memory Retrieval
A sub-agent could decompose requests and trigger multiple retrieval attempts from different angles. The depth of retrieval scales with memory size. More memories mean more creative search strategies. I know I could use GraphRAG or something similar, but that would perhaps defeat the simplicity goal.
Two Use Cases
Explicit Recall: “What’s my marathon time PB?” Direct query, standard RAG.
Implicit Augmentation: You ask “Who’s playing tonight?” and the agent knows you support a specific team because you mentioned it months ago. Or you ask for a training plan and it factors in your VO2 max, injury history, and recent race times without you having to re-explain your fitness level. No explicit query. The context just shows up when relevant.
MCP Memory Service
Turns out someone already built this. MCP Memory Service is an open-source tool that implements this pattern and more.
What I liked:
- Hook-based capture: Enables passively capturing memory.
- No LLMs for extraction: The hooks are extractive, not generative. It relies on pattern matching to identify what is worth saving, so it runs often and fast.
- Dream-inspired consolidation: Async process that decays old memories, clusters related ones, compresses redundant information
- Session-start injection: Surfaces relevant context when you start a new session
- Local-first: SQLite-vec backend with super fast (5ms) reads
- You own the data: Everything stays on your machine unless you choose to sync
The “dream cycle” is a nice touch. Instead of memories accumulating forever, the system periodically consolidates them. Like how sleep helps humans consolidate learning.
What I got working
I set up MCP Memory Service with Claude Code and Msty Studio. The dashboard lets me browse memories by tag (auto-generated).
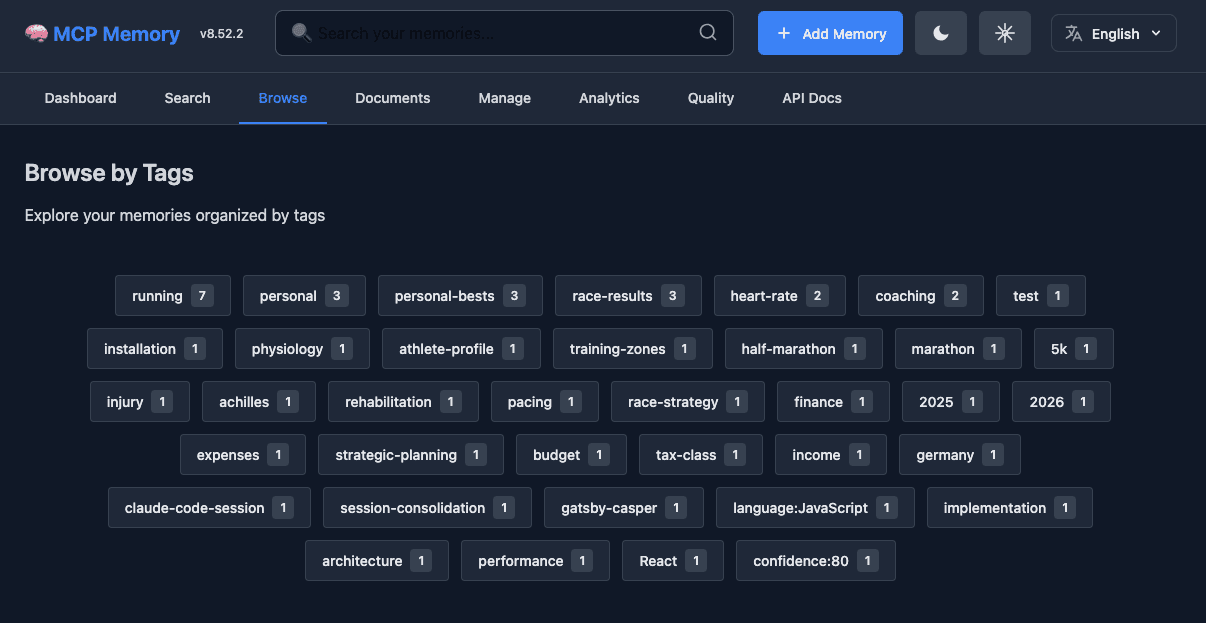
MCP Memory Service dashboard showing memories organized by tags
The real test: querying from a different client. Here’s Msty Studio (local chat client) consuming the same memory:
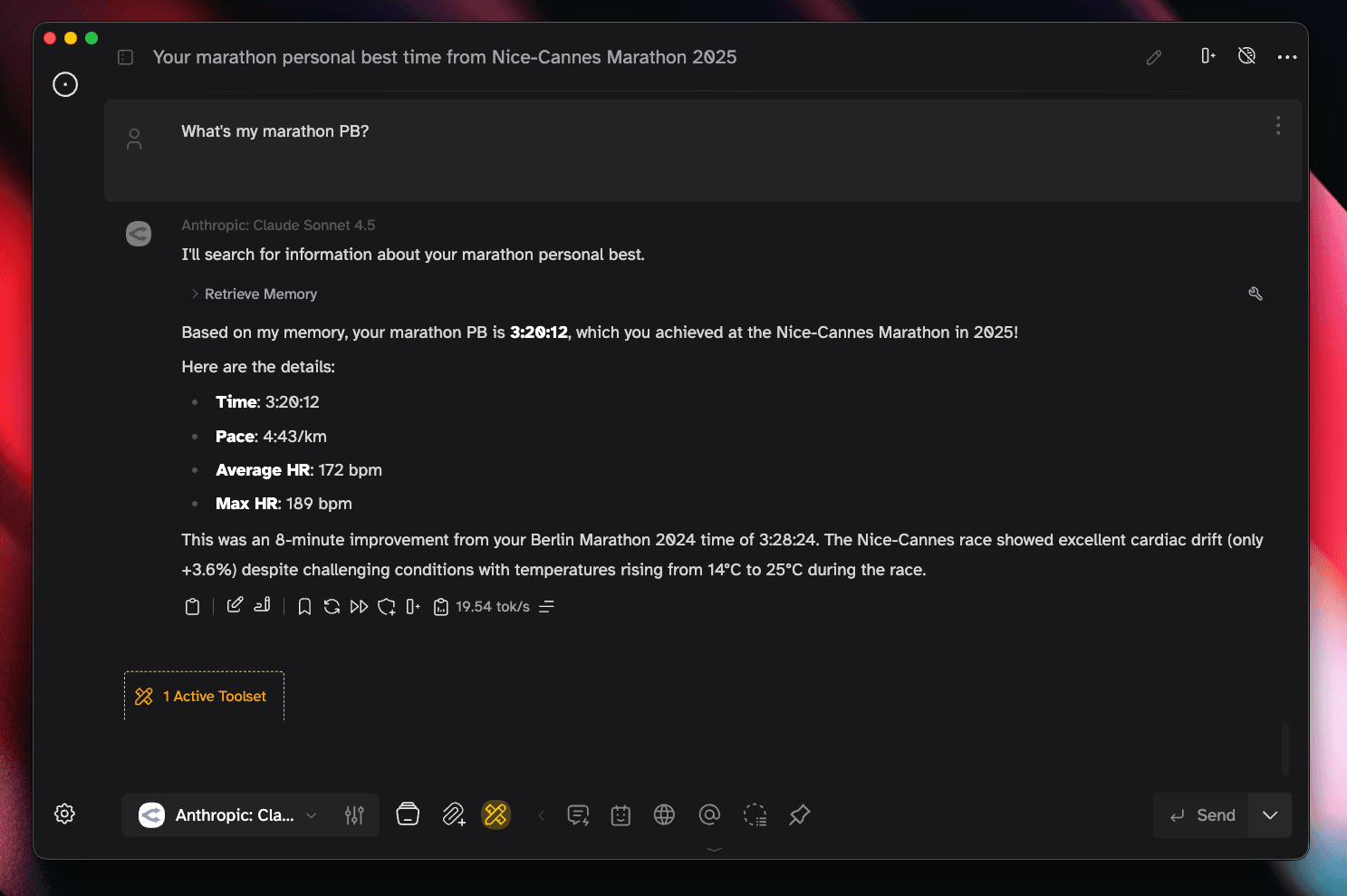
Msty Studio querying memory service
Same memory, different clients. That’s the portability I was after.
Hosted Alternatives
Two other projects worth mentioning:
Letta: Developer platform for stateful AI agents with persistent memory. Their API lets you build agents that remember and improve over time. Works with OpenAI, Anthropic, Gemini. Hosted solution with memory built into the agent layer.
MemSync: Portable memory platform focused on cross-application context. Handles semantic and episodic memories, smart categorization, can import data from ChatGPT, social media, documents. This has probably the biggest feature set.
Both are integrated solutions where you use their infrastructure. MCP Memory Service is more DIY: hooks, local storage, your own vector DB. Different tradeoffs.
Conclusion
Memory is really important for these systems. And perhaps we’ll go in a very different direction in the near future (as some papers already hint), but I really don’t like the idea of having something as powerful as an LLM owning all that information about me.
Social media companies already know a lot about us, but my interaction with Meta or X is usually defined by the content (and ads) they serve. With LLMs, it is literally a chat box. The information the model owns could potentially steer interactions in ways that would feel very uncomfortable without explicit control.
That’s why I think it’s so important, now more than ever, that we own the data. That’s real LLM portability. The memory stays with you, not some company’s servers.
As models become commodities, this might become a big deal.